Early stopping is a technique used while training neural networks to prevent the model from overfitting. Before understanding what actually early stopping is, you must know what is overfitting.
What is Overfitting?
Overfitting is a common problem in machine learning and deep learning where a model learns the training data too well. It happens when the model captures not only the underlying patterns in the data but also the noise or random fluctuations. As a result, the model performs exceptionally well on the training data but poorly on unseen data (test data or real-world data).
Causes of Overfitting:
- Complex Model: Using a model with too many parameters relative to the number of observations can lead to overfitting. The model might capture the noise in the training data, making it perform poorly on new data.
- Insufficient Training Data: If the dataset is too small, the model might not have enough examples to learn the underlying patterns effectively. It might end up learning the noise in the data.
- Lack of Regularization: Regularization techniques, such as L1 and L2 regularization, add a penalty to the loss function to prevent the model from fitting the training data too closely. Without these, the model might overfit.
There are few more causes that could lead to overfitting including data leakage and overly optimisic evaluation metrics.
Preventing the model from overfitting involves following techniques:
- Use More Data
- Regularization
- Dropout
- Early Stopping
- Data Augmentation
And there are still many other ways to prevent overfitting. But in this blog, I would specifically explain about ‘Early Stopping’.
What is Early Stopping?
Early stopping is a form of regularization used to prevent overfitting in machine learning and deep learning models. It involves stopping the training process before the model starts to overfit. The idea is to monitor the model’s performance on a validation set during the training process and stop training when the performance starts to degrade, which is an indication that the model is beginning to overfit the training data.
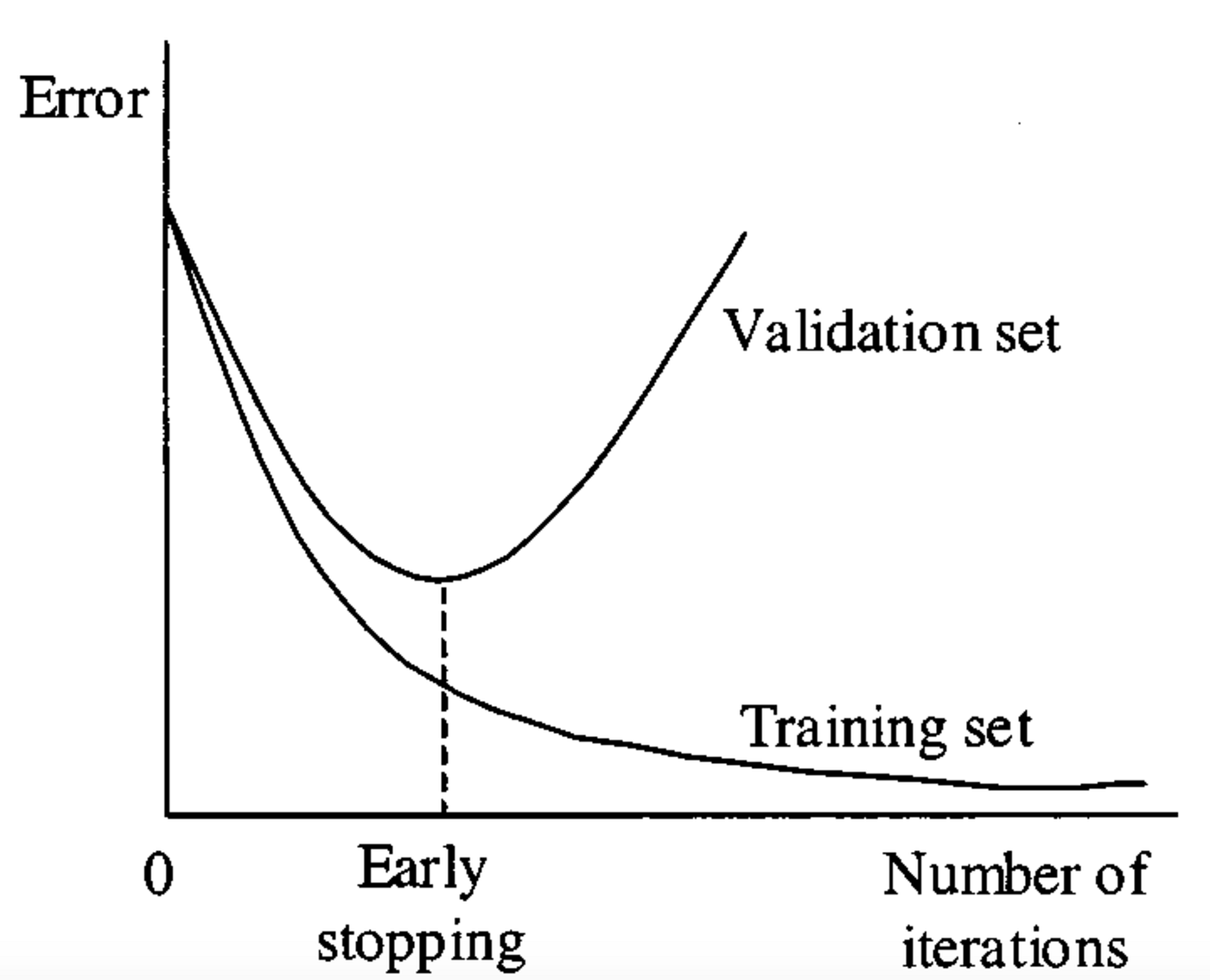
How Early Stopping Works
- Validation Set: During training, a portion of the training data is set aside as a validation set. This set is used to evaluate the model’s performance at each epoch (iteration over the entire dataset).
- Performance Monitoring: The model’s performance on the validation set is monitored at each epoch. Common metrics used for this purpose include accuracy, loss, or any other metric relevant to the problem at hand.
- Early Stopping Criterion: If the performance on the validation set starts to degrade (e.g., the loss increases or the accuracy decreases), it’s an indication that the model is beginning to overfit the training data. At this point, early stopping is triggered, and the training process is halted.
- Model Selection: Since the training is stopped before overfitting occurs, the model at the point of early stopping is typically the best model, as it has not yet learned the noise in the training data
How does early stopping works in the code
To be honest, this is all there is to early stopping. Before finishing this blog, I would like to show you, how to implement early stopping in PyTorch.
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader
from torchvision import datasets, transforms
# Define your model, loss function, and optimizer
model = ...
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.01)
# Load your data
train_data = datasets.MNIST(...)
train_loader = DataLoader(train_data, batch_size=64, shuffle=True)
# Early stopping parameters
patience = 5 # Number of epochs to wait before stopping
min_delta = 0.01 # Minimum change in loss to qualify as an improvement
patience_counter = 0
best_loss = float('inf')
for epoch in range(100): # Maximum number of epochs
running_loss = 0.0
for inputs, labels in train_loader:
# training logic here
# Validation
val_loss = ... # Calculate validation loss
# Check for improvement
if val_loss < best_loss - min_delta:
best_loss = val_loss
patience_counter = 0
else:
patience_counter += 1
if patience_counter >= patience:
print(f"Early stopping at epoch {epoch}")
break
print(f"Best validation loss: {best_loss}")In this example, we’re using a simple model and a placeholder for the validation loss calculation. You’ll need to replace this with your actual validation loss calculation. The key part is the early stopping logic, which checks if the validation loss has improved by at least min_delta from the best loss seen so far. If not, it increments paitence_counter. If patience_counter reaches the patience value, training is stopped.
Remember, early stopping is a form of regularization and is particularly useful when you have a validation set to monitor the model’s performance on unseen data.
If you’ve liked the explanation, you could show your appreciation by giving me a round of applause. And if you would like to understand other ways to prevent overfitting, you could comment below 👇